This project was devleoped in a group for CS441 Machine Learning at the University of Illinois at Urbana-Champaign
Blackjack is a solved game. By following “Basic Strategy”, which is the mathematically optimal way to play, you will reduce the casino’s edge against you to just 0.5%. That is to say, if you bet $100, you could expect to lose $0.50 over time.
To improve your odds, you can count cards. Essentially, you keep track of what cards have been played, and depending on how many high cards are left, you change your bet size. Casinos of course, have developed countermeasures like paying out less when you win or adding more decks of cards into play.
Modeling the Game
Our first step was to model the game. Many simple blackjack simulations online only account for basic hit/stand interactions for singular hands. They have no knowledge of bet sizes, card distribution, or other actions like splitting and doubling. Our simulation modeled all these behaviors and more with a customizable shoe size and payout amounts. This was done so we can test the agents against a wide variety of house rules.
Training the Agent to Play
There is no prexisting dataset we could find about blackjack hands, so we generated all the data from our simulation. As we are training reinforcement learning agents, each action the agent takes will result in some reward. For basic hit/stand behavior, this is simple because either the agent wins or loses at the end of that hand, so we assign rewards of +1 and -1 respectively. When the agent decides to double down, we simply double the reward to +2 and -2. The addition of splitting was not trivial because it increased the size of the reward state.
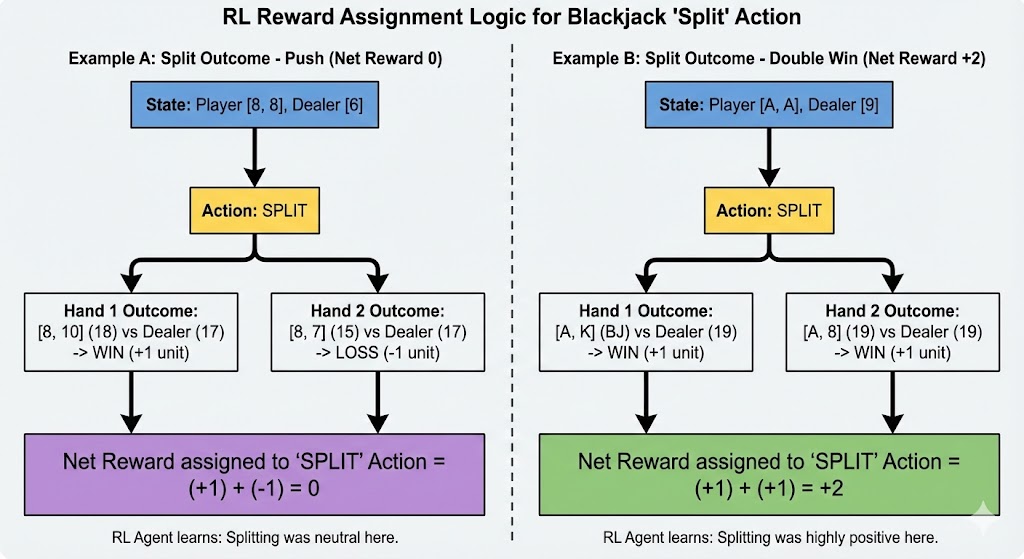
We found that although the trained agent could not beat basic strategy, it was able to learn a strategy chart that was remarkably similar.
Training the Agent to Bet
Traditional card counting keeps a running total of cards seen. Players bet big when the count is “high”, meaning there are a lot of high cards and Aces left. To perfectly model the remaining cards in the deck, you could just memorize every card that has been shown. However, this is not possible for humans. While it would be easy to implement this for our agents, we decided to round our count, just like a real card counter would. Our agent used basic strategy with deviations based on the count while playing. The bet size was completely decided by the agent however. The result was that our agent was actually able to beat traditional Hi-Lo card counting on average.
Future Work
Our experiment with reinforcment learning agents and Blackjack led to some interesting results. To expand on this, we want to increase the realism by adding insurance bets. Additionally, we would like to test different RL algorithms to see which one migh potentially provide better performance.